Webarena
WEBARENA
Motivation
- Autonomous Agents는 인간의 자연어를 통해서
everyday task를 수행해주는 agent임 - Autonomous Agent를 개발하기 위해서는
environment가 필요한데, 현재까지authentic하고reproducible한environment를 기반으로 한 데이터 셋이 아직 존재하지 않았음 - 기존의
over-simplify된 real-world를 표방하는environment들에서 벗어나, Web autonomous Agents 분야의 벤치마크를 만들것임
Contribution
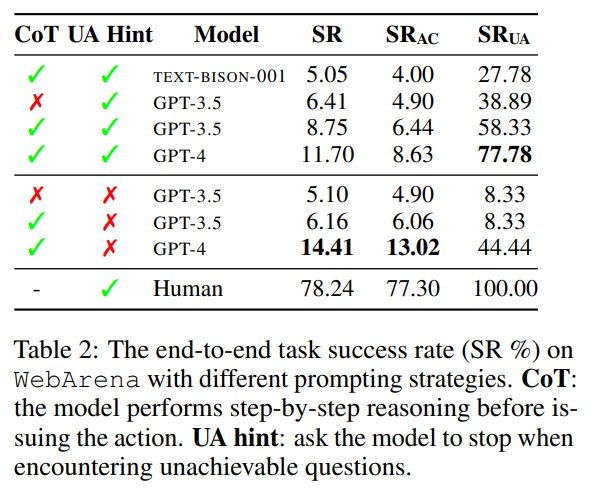
WebArena
- Autonomous Agents가 task를 실행하기 위한
realistic하고reproducible한 webenvironment소개 - 4가지의 다른 도메인을 포함
- online shopping (OneStopShop)
- discussion forums (reddit)
- collaborative development (GitLab)
- business content management (CMS)
- map, calculator, scratchpad 와 같은
human-like task execution을 지원 - domain-specific 한 knowledge를 위해서 위키피디아 지원
Task Benchmark
- 812 개의 long-horizon web-based task를 만듦
- task의 evaluation을 위해서
functional correctness에 집중functional correctness: 실행 결과가desired goal을 달성했는 지 여부
- task의 예시는 아래와 같음

Autonomous Agent Testing with Benchmark
- 제시한 benchmark를 이용해서 저자가 만든 Autonomous Agent를 평가했음
- Autonomous Agent는
few-shot in-context learning기반의 agent이며 LLM은 GPT-4와 PALM-2를 사용few-shot in-context learning: 프롬프트에서 몇개의 예시를 주며 따로 memory를 구성하지 않고 short-term memory만 사용한 agent
- 성능은 task success rate가 14.41% 밖에 나오지 않음 (인간의 performance는 78.24%)
Methodology
WEBARENA
E= ⟨S, A, O, T ⟩
- S : state space
- A : action space
- O : observation space
- T : S x A → S : transition function (deterministic)
POMDP (Partially observable Markov decision Process)
- 어떠한 natural language intent i 로부터 기인한 task를 수행한다는 것은
POMDP로 정의될 수 있음 - 어떠한 시점 $t$에서 agent는 $o_t \in O$ (partial observation) 상에서 $a_t \in A$ 인 액션을 시행함
- 액션의 수행 결과 새로운 $o_{t+1} \in O$ 와 연관된 상태인 $s_{t+1} \in S$ 가 도출됨
reward function
- $r(a, s)$: task 수행의 성공을 평가하는 지표
- a: action 들의 sequence
- s: 모든 상태들
WEBSITE SELECTION
- 4가지 대표적인 웹 사이트 카테고리를 선별
- e-commerce
- social forum platform
- collaborative development platform
- content management systems
- web-based tasks에서 주로 사용되는 세가지 utility-style tools 선별
- map (
POI(points of interest)를 위한navigation과information searching에 사용) - calculator
- scratchpad ( 노트 필기)
- map (
- Wikipedia
- web-based tasks에서 다양한 knowledge 자원을 찾고 획득하는 것은 매우 중요함 ( e.g. 웹 사이트에 대한 유저 매뉴얼)
- 저자는 OneStopShop, GitLab, Reddit, CMS를 구현
- 모두 오픈소스를 기반으로 개발했음
- 데이터는 실제 real-world의 데이터를 어느 순간 캡쳐해서 사용 (Gitlab의 경우 실제 프로젝트를 기반으로 한 버전)
OBSERVATION SPACE

-
왼쪽부터 screenshot, DOM tree, accessibility tree
- 처음으로 제시된
mutl-tab web-based tasks임 multi-tab functionality는 모든 작업을 하나의 탭에서 하는 것 보다 인간의 웹 브라우징 행동에 더욱 적합함- 페이지 렌더링을 설정에 따라서 3가지로 다양하게 지원함
- DOM tree: (과거의 연구들에서 많이 사용)
- screenshot
- accessibility tree:
relevant하고useful한 element들만 포함 ( DOM tree의 subset임)
ACTION SPACE
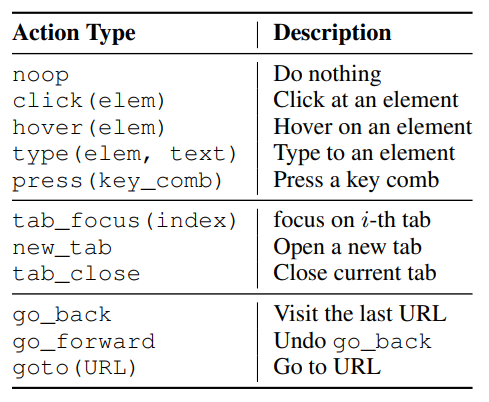
- 3단계로 action을 나눴음
- element operation
- tab-related action
- URL navigation action
BENCHMARK SUITE OF WEB_BASED TASKS
INTENT COLLECTION
complex하고creative한 task를 만들기 위해서realistic한 intents를 만드는 것에 집중함- annotators 들을 이용했음
annotator 들에게는 아래와 같은 3가지 기준을 적용하라고 제시
abstract하고high-level의 intent 생성 (레딧의 과학 게시판 클릭 x, 레딧의 과학 게시판에 환영 인사남기기 o)- intent는
creative해야 함 (레딧 계정 생성 x, 나의 깃랩 아이디와 똑같은 레딧 계정 생성) - intent는 구조화 될 수 있어야 함. (create a Reddit account identical to my GitLab one → create a {{site}} acount identical to my {{site2}} one)
INTENT ANALYSIS
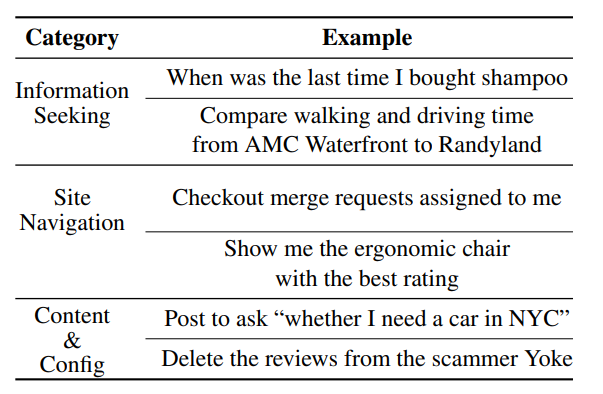
- 만들어진 241개의 템플릿들과 812개의 intents들은 위와 같이 3가지로 나누어짐
- Information-seeking : text로 된 응답을 원하는 task.
user-centric컨텐츠에 집중함. 간단한 탐색과 general 한 질문에 대답하는 것에 집중 - Site navigation : 다양한 웹페이지들을 탐색하면서 수많은 interactive 한 요소들과 상호작용함. 주로 어떤 사이트의 특정한 섹션에 도달
- Content and configuration operation : create, review, configure content or settings. 웹 환경에서 어떠한 명령을 수행하는 작업들
Evaluation ANNOTATION

Evaluating Information Seeking Tasks
- exact_match : 실제 원하는 답과 agent의 답이 정확히 일치하는 경우
- must_include : 실제 원하는 답이 agent의 답에 포함되어 있는 경우
- fuzzy_match : 실제 원하는 답과 agent의 답이
semantically equivalent한 경우 ( GPT-4를 사용하여 measure)
Evaluating Site Navigation and Contente & Config Tasks
- locator를 이용해서 실제 웹 사이트에서 정보를 확인하고 agent의 답과 비교
Experiment