Fuzzingviallm
Fuzzing via LLM
Motivation
- 기존 fuzzer 들은 아래와 같은 3가지 문제점이 있었음
C1: Tight coupling with target system and language
- 타겟 프로그램인
SUT(System Under Test) 나 타겟 프로그래밍 언어에 매우 최적화되어 있음 - 타겟 프로그래밍언어에 최적화 되어 있기 때문에 새로운 퍼저를 디자인하거나 구현하는 것이 매우
time-consuming한 일임 - 예를 들어 linux system call을 상대로한
syz-kaller의 경우에는 몇만개의handcrafted rules이 존재함
C2: Lack of support for evolution
- 주로 기존 연구들은 어떠한 타겟 언어나 SUT의 특정한 버전을 타겟으로 했음
- 따라서, 타겟 언어나 SUT이 변경된다면 기존의 퍼저는 변경된 프로그램에 대해서 효과적이지 않음
C3: Restricted generation ability
- 기존의
generation-based와mutation-basedfuzzer는input space에서 매우 제한적인 부분만 커버했음 generation-based fuzzer는 보통 전체 full language grammar 의 subset을 사용하는데, 전체 언어 특징 중에 일부분에만 적용가능함mutation-based fuzzer는 mutation operator에 의존하며 높은 퀄리티의 시드가 필요함
위 3가지 기존 퍼저의 문제점 때문에 본 논문에서는 이를 LLM을 이용해서 해결한 새로운 퍼저 아키텍쳐를 고안함
Contribution
- 매우 다양한 input language 와 각 language 별로 많은 features 들을 커버한
universal퍼저를 제안함
Universial Fuzzing
- 넓은 범위의 input 들을 이용해 다양한 SUT를 대상으로 한 퍼저를 개발함
Autoprompting for fuzzing
general하고targetted한 fuzzing 을 지원하기 위해서 새로운 autoprompting 기법을 제시함
LLM-powered fuzzing loop
- 선택된 예제들과 generation strategies에 따라서 반복적으로 prompt를 변화시키는 알고리즘을 제안함
Evidence of real-world effectiveness
- 6개의 인기있는 언어들과 9개의 실제 SUT를 대상으로 퍼저를 검증함
Continuous updating
- https://fuzz4all.github.io 에서 퍼저를 계속 유지보수함
Methodology
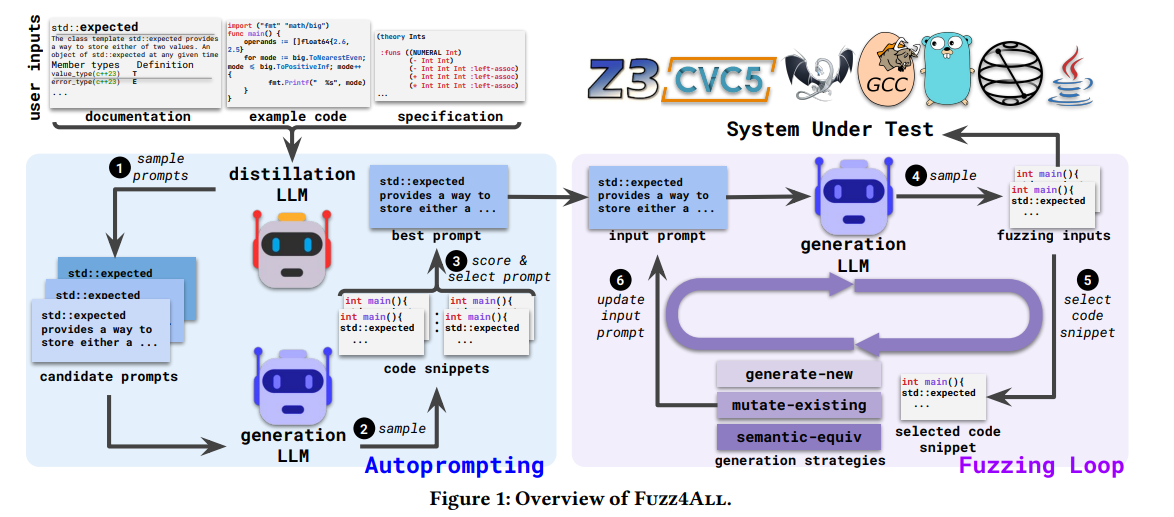
- FUZZ4ALL은 6가지 단계로 나누어져 있음
- 메인으로는 distillation LLM과 generation LLM이 있음
- distillation LLM의 역할은 prompt를 생성하는 역할
- generation LLM은 실제 SUT에 들어가는 input sample을 생성하는 역할
- 크게는 Autoprompting 단계와 Fuzzing Loop 단계로 나누어져 있음
Autopromting

- Autoprompting 단계에서는 user input 으로 부터 퍼징에 알맞는 prompt를 생성함
- 그냥 plain 자연어로부터 generation LLM을 위한 prompt를 생성하는 것은 매우 비효과적이므로 (ablation study를 통해 알아내었음) input prompt를 정제해서 사용함
- 정제하는 알고리즘은 위와 같음
정제 LLM
\[M_{D}(prompt|userInput,APInstruction)\]
- $M_{D}$ : distillation LLM을 뜻함
- userInput: SUT의 description, code snippet과 같은 처음 입력 seed를 뜻함
- APInstruction: autopromting을 위한 prompt를 뜻함
Please summarize the above information in a concise manner to describe the usage and ufnctionality of the target
- APInstruction 예시
- 정제 LLM은 처음에 temperature 0으로 greedy output을 생성 (타 연구에서도 사용한 방법 e.g.) program synthesis)
- greedy output은 타겟 SUT를 확실하게 실행할 수 있는 신뢰도가 높은 prompt
- 그 다음 teperature를 높여서 더욱 다양한 prompt를 생성
Scoring Function
Fuzzing Loop에서 사용되는 prompt를 만들기 위해 정제 LLM이 생성한 여러 prompt를 scoring 해서 가장 좋은 prompt 를 사용
\[\sum_{c\in M_{G}(p)}[isValid(c,SUT)]\]- 간단한 fuzzing을 통해 각 후보 prompt의 성능을 평가함
- 각 prompt들은 generation LLM의 인풋으로 사용되어 다양한 code snippet 들을 생성
-
code snippete 들을 scoring 하여 가장 높은 스니펫들을 생성한 prompt를 채택
- $M_{G}$ : Generation LLM을 뜻함
- $p$ : 후보 prompt를 뜻함
- isValid(c, SUT): 만들어진 code snippet이 타겟 SUT 상에서 실행이 되는 지 여부를 뜻함
본 논문에서는 scoring function으로 타겟 SUT상에서의 실행 여부를 채택. 논리적으로 말이 되는 코드를 얼마나 많이 생성하는 prompt인 지를 선정
Fuzzing Loop

- Fuzzing Loop 단계에서는 정제 LLM단계에서의 inputPrompt와 여러 instruction을 기반으로
Oracle에 의해서 버그로 판명된 Input들을 계속 생성함
- Line3 : generation LLM으로 인풋들을 생성
- Line6 : 타겟 SUT를 대상으로 타당한 생성된 인풋들 중에 랜덤으로 하나를 샘플링
- Line7 : Instruction Strategy 중에 하나를 샘플링
- Line8 : 샘플링한 example과 instruction을 이용해서 프롬프트를 구성하고 생성 LLM을 이용해서 새로운 인풋들을 생성
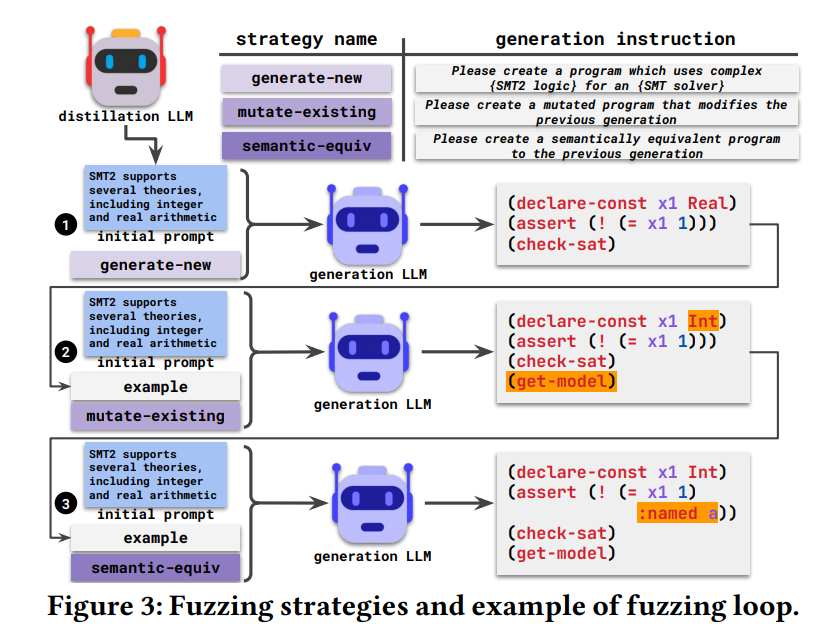
- instruction 들은
generate-new,mutate-existing,semantic-equiv3개로 구성됨 - generate-new : 새로운 인풋을 생성 (
generatio-based fuzzer로부터 기인함) - mutate-existing: 기존 인풋을 변형한 인풋 생성 (
mutate-based fuzzer로부터 기인함) - semantic-equiv: 기존 인풋과 semantically equivalent한 인풋을 생성
저자들은 정제 LLM은
GPT-4를 사용하였고 생성 LLM은 hugging face의StarCoder를 사용하였음. fuzzing loop에서 계속 인풋을 생성하는데에는 역시 gpt-4를 사용하면 너무 비용적인 문제가 많이 들 것 같음